根据这些差异,NEI的构成尤其需要注重劳动力和技术投入指标。除此之外,新经济人力资本密集的特点也需要企业在成长初期有一个相对更长的学习和积累。
在此基础上,NEI指标评价体系参考美国信息技术和创新基金会(ITIF)发布的《2014美国各州新经济指数》(2014 State New Economy Index)报告指标体系、硅谷指数(Silicon Valley Index)等国际知名新经济和创新指数体系,结合中国经济发展特点和数联铭品的数据优势制定了以下新经济指数的指标体系。
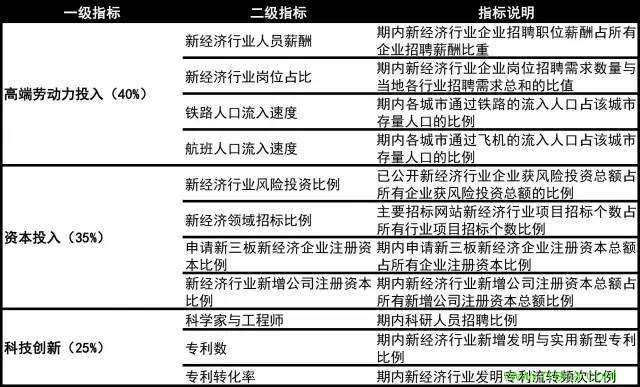
NEI指标体系共有高端劳动力投入、优质资本投入与科技和创新三大类一级指标(分别代表了新经济发展的劳动力投入、资本投入、科技与创新投入)和11个二级指标(表3)。这些指标可以综述为以下几个方面:
1.高端劳动力投入
高端劳动力投入是新经济体系的基本特征。高端人才去哪了,哪个行业、哪个地方的经济就充满了活力。“高端劳动力投入”由“新经济企业岗位占总招聘岗位”、“新经济企业总薪酬占全部行业总薪酬”、“铁路人口净流入速度”、“航班人口净流入速度”这4个二级指标构成。
2.优质资本投入
和人才一样,资本流入的方向是经济发展的未来。外资是改革开放以来带动中国“新经济”发展的重要力量。当前风险投资市场也已日趋成熟,成为中国新经济发展的重要推动力量。“资本投入”包括“新经济行业风险投资占总风险投资比例”、“新经济领域招标比例”、“申请新三板新经济企业注册资本占所有申请新三板企业总注册资本比例”、“新经济行业新增公司注册资本占所有行业新增公司总注册资本比例”这4个二级指标构成。
3.科技与创新
创新能力是区域新经济发展的引擎,各企业的高级专业化人才、科学家和工程师的数量是创新的主体。我们通过一个区域的高级专业化人才数量、科学家和工程师保有情况及新增专利数量来衡量新经济的增长在总经济增长中的重要性,共包含“新经济雇佣的科学家与工程师占总体科学家和工程师的比例”、“适用于新经济的专利占总专利数量比例”和“适用于新经济的专利转化占总专利转化的比例”这三个指标。
根据以上3个一级指标和11个二级指标,NEI将产生两大模块的指数产品:1,时间纵比指数;与2,区域横比排序。时间纵比指数重点在于衡量各区域、各行业、各指标随时间的变化。区域横比指数用于衡量同一时段不同区域的新经济综合发展水平,重点在于区域对比,发现各地的长短板。
表3:新经济指数的指标体系
三、获取大数据
网络公开的大数据是NEI的基础数据。在制作NEI的过程中,我们使用了大量数据,包括企业网络上的公开招聘信息、新成立企业工商登记信息、风险投资数据、招标投标数据、三板上市数据、各类专利及专利转化数据等。为了获取准确、客观的新经济指数,详细讨论各类企业行为的季度趋势,我们不仅会收集指数发布当月的数据,还会向前回溯,积累更多的历史数据。
至今为止,NEI所用的累计数据包括5200余万条招聘信息、270万条新企业登记信息、376万条招标/投标数据、2.8万条风险投资数据、5000余条三板上市数据、580万条专利登记数据、30万条专利转移数据,另外还包括用以计算城市人口流动信息的实时铁路出票量数据、机场航班流量数据。全部合计,我们的原始数据储存总量已经超过了100G。为了计算2015年8月至2016年2月这半年的指数,我们产生的数据总量合计超过370G。
除了数据量庞大这一特点外,构建新经济指数的数据还具有较好的全国代表性。其中,企业登记、招投标、风险投资、三板上市、专利情况数据均为2015年七月以来全国所有可得数据。人口流动数据囊括了所有的航班信息、列车运行状况;200公里以上的长途客运周转量(人公里)和运输人次指标中,我们的数据量占全国总数据量的74%。我们的招聘数据也包括了多家重要招聘网站的完整信息,从一、二千元每月的低技术岗位到50000元每月的高技能岗位,覆盖全国各个行业。虽然有部分数据没有达到总体的规模,但是由于新经济指标的构建采用的是比例指标而不是绝对值,这些指标随样本数量多寡的变化很少。因此总体上,我们的数据覆盖程度使构建全面反应我国新经济发展状况新经济指数成为可能。
为了在每个月的月初发布NEI,我们需要用到从上个月25日到前一个月26日,共一整个月的数据从原始数据开始计算新经济指数。
四、行业识别
大数据的特点之一,是数据的庞杂性。我们手中的原始数据,是一条条企业行为。例如,A企业在某招聘网站上发布了一条招聘信息,B企业获得了1000万元的风险投资。为了让离散的企业数据聚合产生价值,我们首先必须研究如何将这些企业聚类、合并。而聚类的最佳标准则是行业与地域。另一方面,新经济指数也要求我们将属于“新经济”行业的企业进行准确的归并。
地域信息的抽取相对容易,我们只需要识别企业名称或者企业在其网站上的登记信息,绝大部分情况下都可以顺利的识别出一个企业的准确地址。但是识别行业则是一个较为复杂的过程。想象一下,当人们看到一个企业的名称时,如何判断其行业所在?一般来说,首先会观察这个企业名称是否包含某些关键词。例如,包含“网络”一词的,一般属于信息技术企业,包括“能源”一词的,可能是新能源企业。
人们将某些关键词关联到某个行业,凭借的是经验。但是,计算机并没有这样的经验,因此,我们首先需要让计算机学会如何通过观察一个企业的名称来准确判断其行业,具体过程如图1所示。
第一步,我们必须找到合适的训练样本。基于2013年工业普查数据与2008年的经济普查数据库,我们用企业名称和详细的行业信息(精确到四位数代码),来训练企业名称到行业的映射,但弱点在于,工业普查数据完全集中在制造业,对计算机学习其他行业的企业名称映射并无帮助;2008年经济普查的时间又太过久远,对该指数所说的“新经济”涵盖不全。
因此,我们使用2015年全年的270万家新成立企业作为训练样本,找到这些企业与行业之间的映射关系。映射的路径为企业的经营范围——《统计用产品分类目录》——《国民经济行业分类》。最后,我们根据经营范围映射成功的行业关键词的个数以及出现顺序,判定该企业的行业。
例如,当我们在一个企业的经营范围中看到“电子血压计”时,可从《统计用产品分类目录》查询到其行业代码3584。若同时有多个行业的关键词被匹配到经营范围中,则按照关键词在文中的出现顺序分别分配从大至小的一列权重后,加权计算该企业匹配到的行业总分来确定该企业的确切行业。
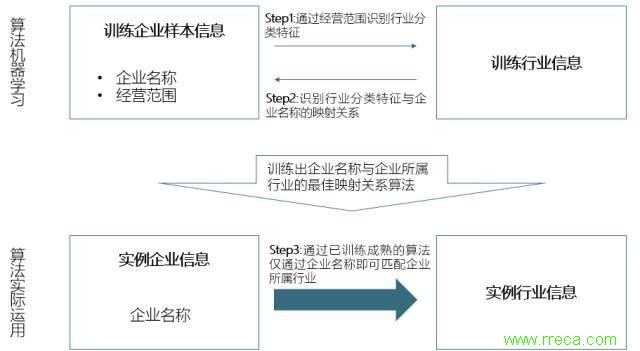
图1:新经济指数指标体系的行业识别
第二步,我们将这部分确定了行业的训练样本取出,对其企业名称进行自然词语分割,并以每个企业的名称短语组合作为自变量,企业的实际行业作为因变量,进行多元logit回归。我们选择了出现频率在前200个的有意义短语(“有限”、“公司”等不具备实际行业信息的短语不包括在内)作为预测因变量,计算当某些特定短语在企业名称中出现时,该企业落入某些特定行业的概率会出现怎样的变动。我们将经过训练的识别程序引用到原有训练样本上,并发现200个短语的行业判断准确度达到了95%左右,这使我们能够有信心使用该程序来判断其他企业的行业信息。
第三步,我们对所有企业都进行分词,同时应用第二步算出的短语行业识别程序,计算每个企业的行业概率分布。为了保持预测的效率,避免带有新词语的企业无法被准确判断行业,我们每个月度都将更新企业短语。
五、生成新经济指数
对企业的行业进行准确分类后,我们需要计算新经济行业企业在经济产出中的份额。首先,考虑一个一般的生产方程,其中K代表资本,H代表人力资本,A为技术水平,L则为劳动力,w为各个要素投入的产出弹性。
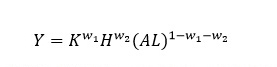
假设每个要素中,有被投入新经济,容易算出,当资本中有的份额被投入新经济,人力资本有的份额被投入新经济,劳动力有的份额被投入新经济时,新经济占总经济产出的份额可表达为下式:
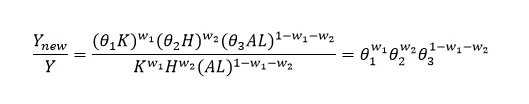
两边取对数,可得:
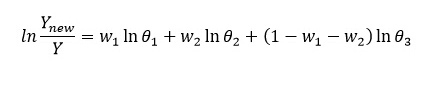
当我们将生产函数一般化,不仅只包括劳动资本与技术,而是包含更多二级指标时,每一个指标的分权重会减小,使得上式中的对数符号去掉之后等式两边仍然近似成立,即得到下式:
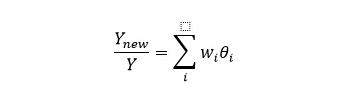
六、新经济指数指标权重的确定
确定新经济的指标权重实际上等价于确定新经济行业各要素投入的产出弹性,实践中包括两种方案。
其一是经验数据法,即根据国际经验与历史经验首先判断各个投入成份的产出占比大小。根据数据,2014年中国第三产业的劳动者报酬占增加值比重约为47.2%,具体到行业,信息传输业的劳动者报酬占比为23.4%、科学研究业的劳动者报酬占比为49.7%。考虑到新经济行业是“以高质量劳动力为主要要素投入”的行业,我们将劳动者投入的权重定为接近上限的40%,对资本和技术则分别规定35%和25%的权重。同时,所有二级指标按简单算术平均合成相应一级指数。经验数据算法的优势在于我们将有一个具有理论框架的新经济指数,如果未来有新的指标,我们可以将这些新的指标纳入全要素生产率、劳动或者资本的一项中,进行内部权重微调。
但劣势在于,如果新经济的发展十分迅速,各个部分的生产弹性变化很快,我们将不得不考虑大量变动一级指标权重。
其二是主成分分析法。主成分分析法的宗旨是依次找到经济投入这一矩阵的奇异值,即首先找到方差最大的那一组向量所对应的奇异值,再找到方差次大的向量所对应的奇异值,以此类推。主成分分析法的优点在于他能够以最小的信息量,对结果进行最好的预测,因此在预测效率上是最高的。但缺点在于,我们没有一个合适的理论框架来阐释我们的权重选择,并且这样的权重只是来源于历史数据。问题是在应用到未来数据中去,如何选择计算权重的历史数据,选择哪个区间的历史数据,都较为随意,使得整个新经济指数指标体系的建立缺乏客观性。
在综合两种算法的优劣后,我们决定采用两种算法的长处,在初期采用经验数据法,根据理论模型设置各指标权重。未来,则更多地使用主成分分析法,根据预测效果和历史数据的变化,进行权重微调,以达到用指数来客观观察中国新经济发展情况的效果。
七、NEI的下一步
新经济将引领未来结构调整的方向,是新常态下经济增长的新热点。新经济数据,是衡量结构调整步伐,判读总体经济走势,把握投资机会的基础材料。以大数据为基础的新经济指数,可以更加及时反映新经济变化快的特点,更加适合网络+时代的投资分析与决策。
NEI第一次可以较为清晰地展示新经济与旧经济之间的关系。新经济的快速成长能否有效抵消旧经济下滑的压力,是转型与稳增长能否同步实现的关键。今天发布的新经济指数有助于我们理解新经济相对于旧经济的变化,旧经济过快调整或通过就业、收入和服务需求的渠道拖累新经济,其影响的量级如何尚不得而知,NEI是跟踪评估新经济变化的一个主要指标。
NEI是一个详实的指标体系,一些细项指标本身代表了新经济活动的一个侧面。大数据可以捕捉新金融和其他新业态的早期趋势,是互联网时代资讯开发的新渠道,更可以结合线下和传统的统计数据,勾画出一幅更加完整、动态的新经济图像。
NEI还可以展示经济发展的地域差异,有利于政策的差异化和资源的优化配置。在新经济指数的基础上,可以对主要城市新经济活跃程度进行排名。新经济发展或是继工业化后人口跨地区流动的重要方向标,结合人口出行大数据,可以刻画人口流动热力图,指引消费和服务业资源的跨区配置。
考虑到大数据的收集、清理以及参数的设定都需要时间来逐步完善,现发布试行版,待满一年后重新评估调试后正式发布。正式发布的NEI将主要考虑以下几个方面的变化:
(1)季节性因素的影响及调整。新经济活动占比在很大程度上剔除了季节性因素的影响,但新经济活动的季节性是否有异于传统经济,仍需要观察。一些月度波动较大的因素,需要通过移动平均的方式进行平滑处理。
(2)新经济行业需要不断调适,更加准确地反映产业升级和新业态的发展,力争全面涵盖新经济活动,准确反映新经济的新趋势。
(3)各子项因素的权重将逐步完善,根据历史数据,采用主成分分析法进行调整。
【本文执笔:陈沁,BBD Index首席经济学家;沈明高,财新智库莫尼塔董事长兼首席经济学家;沈艳,北京大学国家发展研究院教授、财智BBD新经济指数首席顾问】






